Here it is, my very first infographic:

Disclaimer: It may look easy but its not. i.e. making the infographic….. and building a successful startup of course.
Here it is, my very first infographic:
Disclaimer: It may look easy but its not. i.e. making the infographic….. and building a successful startup of course.
In the startup world, there are several terms that are often thrown around which can become pretty confusing for the uninitiated. So to avoid any head-scratching moments, here is a list of the key few and what they mean:
Note: Some of these terms shall be used again in an upcoming post “Steps to building a successful startup”, so make sure to go through all of them!
1. USP – Unique selling proposition
That special factor that differentiates your company from others and provides benefit to consumers of your product/service. Could be a novel technology, a new approach to doing something already available that either makes it cheaper or more attractive, a special business culture or a novel focus on a niche market.
2. Deep tech
This is a rather new one and is used to describe companies that use completely novel technology as opposed to currently available technology. Makes the company look more sexy to investors. Not to be confused with deep learning which is a fancy term thrown around by tech geeks to describe a better version of machine learning.
3. Runway
How much time you have before your investor money runs out.
4. B2B, B2C
Often used to describe the nature of your product/service, whether its being sold to businesses i.e. business to business; or directly to consumer i.e. business to consumer
5. Exit
How you want the company to end successfully and make everyone (i.e. investors and startup founders) rich. Either comes in the form of an IPO (initial public offering) where the company gets listed on a stock exchange which allows investors a chance to liquidate their shares, or a buyout, where another company buys the founded company and investors get their ROI (see next).
6. ROI – Return of investment
What the investor would receive when the company exits. Usually expressed as a ratio: (gain from investment – cost of investment)/cost of investment.
7. SaaS – Software as a service
A company model where licences/subscriptions are sold to users to obtain access to a cloud-based software.
8. Vesting
Where employees/co-founders get given shares but receive them over a period of time rather than at one go in order to get them to stay at the company for a longer time. It may follow a vesting schedule where one gets a small portion every year and may include a “cliff” where shares are given only after a fixed period.
9. Unicorns, centaurs and ponies
Derived from Silicon Valley and are used to describe companies with different scales of valuation. Unicorns are valued at over $1 billion, Centaurs at over $100 million and My little Ponies at greater than $10 million.
10. IP – intellectual property
Refers to a creation of the mind that you want to protect, usually by patenting it or keeping it extremely secret (e.g. the recipe for Coke).
11. Traction
Evidence that the company is growing or has potential for growth. This can be shown via customer response or actual revenue.
12. Valuation
This is how much your company is worth in the eyes of investors. Its pretty difficult to decide this in the early stages. Usually investors will come up with this by analyzing similar companies (i.e. your competitors) and seeing how much they are valued. See here for an infographic on the calculation process. The valuation can be affected by factors such as founder reputation or prior success, traction, current distribution channels (e.g. if you already have an established channel like a blog with a million views by which you can reach many potential customers), and industry buzz like if you happen to be working on the hot topic of the month.
Valuation is also split into pre-money and post-money valuation. If your company was valued by an investor as being worth $1 million for example. That is the pre-money valuation. If the investor decides to invest half a million, the post-money valuation = $1 million + $0.5 million = $1.5 million and the investor now owns 33.3% of your company.
13. Funding rounds: Seed, Series A, B, C..
The seed funding round is the first investment round where a company gets money – usually from friends/family, angel investors, incubators/accelerators or via crowd-funding. Following which a company could approach VCs (Venture Capitalists) for funding rounds named Series A, the next funding round being Series B and so on. The number of rounds can apparently go on as long as the company wants to remain private and not do an IPO. Uber for example went up to Series G! Another nice infographic with more detailed info on startup funding sources here.
14. Venture Capital
Money from a fund run by venture capitalists which pools money from various investors and invests in a portfolio of companies.
15. Angel Investor
A rich individual that provides capital to a startup in return for a stake in the company.
16. Crowd-funding
Getting money from the public masses. Often done through online platforms , see here for a list.
17. Accelerator/Incubator
An organisation that supports startups either in terms of office space, funding, mentorship/guidance and access to professional networks. Most of them take some equity from the company in exchange. Accelerators are said to be for more mature startups while incubators for the newborns but they are often used interchangeably.
18. Due Diligence
A detailed investigation into a business done by investors/companies looking to acquire it. Often involves in-depth analysis of a business’ assets and liabilities to determine its commercial value.
19. Proof-of-concept
Demonstration that your idea is actually feasible and is often required to get VC funding.
20. MVP – Minimum viable product
The simplest version of your product that is required to achieve proof-of-concept.
21. Pivot
When you have to quickly alter the position of your company either by changing the target market, or the application of your product in order to survive in the market.
22. NDA – Non-disclosure agreement
What one signs when a company/individual doesn’t want you spilling their secrets.
23. CRM – Customer relationship management
A system or software used by companies to consolidate customer information so that staff can easily access, manage and record interactions with customer, with a goal to track business performance and drive sales.
24. Burn rate
The money a company is burning through every month before breaking even or making profit.
25. Bridge loans or Mezzanine financing
These are hybrid loans in the form of cash or equity/options given to more mature companies which are cash-positive usually in preparation for an IPO.
26. SOPs – Standard operating procedures
Step-by-step instructions of procedures important for running of the business that employees follow to improve efficiency and communication within organization and to maintain a high quality and uniformity of the product.
I am currently reading “The Gene” by Siddharta Mukherjee, a wonderfully-written book on the history of our genes. Mukherjee does well to capture the key events in how we have come to understand (and manipulate) genetics today. Not only focusing on the famous names in science but also highlighting the lesser known characters who played a large role in how history unfolded. It’s an eye-opening and interesting read for scientists and non-scientists alike and increases your respect for a simple little molecule that has been and continues to be the subject of intense study and debate.
DNA or deoxyribonucleic acid came to be discovered as the transmitter of genetic information only after much effort was spent disproving that other molecules were not doing the job. As compared to proteins, it was seen to be a “stupid” molecule due to its simple composition of four bases – adenine (A), thymine (T), guanine (G) and cytosine (C). Only after its structure was revealed in Rosalind Franklin’s X-ray crystallography photos and deciphered by Watson and Crick, was the simplicity and elegance of the molecule fully appreciated. The specific pairing of A-T and G-C bases via hydrogen bonds (termed Watson-Crick pairing) while sitting opposite each other in a double-stranded helix formed the basis of the genetic code. Hydrogen bonds can be broken with much lower energy, which enables the two strands to separate easily, allowing one strand to serve as a copy in the synthesis of another. This allows the genetic code to be transmitted to daughter cells or translated into other molecular forms such as RNA (ribonucleic acid) and protein, the latter being the so-called workhorses that carry out the encoded function of a gene.
More to DNA than meets the eye
More secrets about DNA were revealed following Watson and Crick’s discovery. The pair based their findings on a particular form of DNA called B-DNA which is the predominant form that DNA takes in water. Further structures – supercoiled, A-DNA (occurs in RNA or RNA/DNA duplexes), Z-DNA (left-handed helix) and H-DNA (triple-helix) were later discovered. See here for a more detailed write-up on some of them. Apart from Watson-Crick base-pairing, DNA can also form hydrogen bonds called Hoogsteen base pairs. See below for the difference:
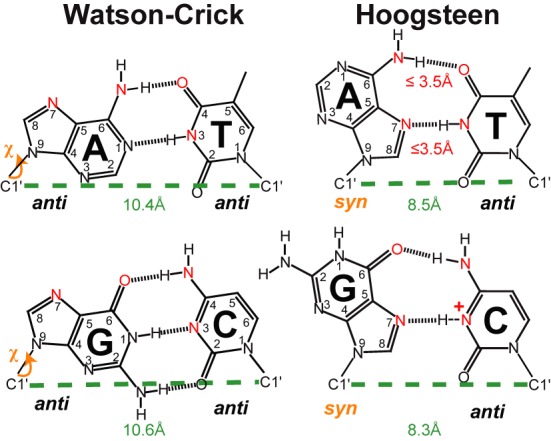
“Shown are WC and HG A•T and G•C bps with highlighted key geometrical differences. Heavy atoms involved in HG hydrogen bonds (in red), syn χ angle (in orange) and constricted C1′–C1′ distances (in green). Average C1′–C1′ distances from the survey are shown for each base-pair type.” Comment and image from: Zhou, H., Hintze, B. J., Kimsey, I. J., Sathyamoorthy, B., Yang, S., Richardson, J. S., & Al-Hashimi, H. M. (2015). New insights into Hoogsteen base pairs in DNA duplexes from a structure-based survey. Nucleic Acids Research, 43(7), 3420–3433. http://doi.org/10.1093/nar/gkv241
Hoogsteen base pairs form when one of the bases has flipped 180 degrees into its so-called syn transition, binding to another base in the anti transition. This results in the two bases being closer together and the angle around the glycosidic bond (χ) being altered which modifies the DNA strand structure. First discovered by Karst Hoogsteen in 1959, it is mostly observed in protein-DNA complexes, damaged or modified DNA and in stretches of AT repeats at an overall incidence of ~0.3% of all base-pairs.
G quadruplexes – what are they?
Hoogsteen base pairing allows DNA to take on more complicated structures such as triple helices or even quadruplex structures, increasing the functional diversity of DNA. G quadruplexes are formed when two or more G quartets/tetrads are stacked on top of each other. One G quartet consists of four guanines hoogsteen base-paired with each other in a circle, surrounding a stabilizing positively charged ion such as Na+ or K+ (but not Li+). The guanines can be from the same strand (intramolecular) or different strands (intermolecular), associating with each other via folding of the DNA/RNA. Once formed, G quadruplexes are thermodynamically stable (even more than B-DNA in vitro), and their conservation especially among mammalian species indicates they may perform important biological functions.

“G-quadruplex structures are polymorphic and can be sub-grouped into different families, as for example parallel or antiparallel according to the orientation of the strands and can be inter- or intramolecular folded. The type of structure depends on the number of G-tracts in a strand.” Image and comment from: Rhodes, D., & Lipps, H. J. (2015). G-quadruplexes and their regulatory roles in biology. Nucleic Acids Research, 43(18), 8627–8637. http://doi.org/10.1093/nar/gkv862
G quadruplexes have been studied by gel electrophoresis, nuclear magnetic resonance, chromatography, and mass spectrometry and can even be specifically bound by antibodies and drugs (pyridostatin, PDS). They are found enriched on the 3′ terminal regions of telomeres, and inhibit the activity of telemorase, preventing telomere extension. They are also found on 3′ and 5′ untranslated regions in DNA, with more than 50% of genes containing G quadruplexes in their promoters – interestingly more so on proto-oncogenes than house-keeping or tumour suppressor genes. This indicates they may have some role in gene regulation, which was supported by gene expression changes being induced by G quadruplex stabilizing ligands and by associations of G quadruplexes with proteins involved in transcription and replication. The presence of G quadruplexes are largely associated with gene suppression and their additional effects on telomeres makes them a prime target for cancer treatment.
A recent paper by Shankar Balasubramaniam’s group has characterized the presence of G quadruplexes in purified polyadenylated (polyA) RNA isolated from human HeLa cells with the use of reverse transcriptional stalling in presence of Li+ vs K+ vs K+/PDS, followed by deep sequencing:

“The BASP1 (chr5:17,276,185-17,276,254) example here shows a drop in coverage (from 3’ to 5’ direction) in K+ and K++PDS conditions due to rG4 formation, whereas coverage is generally uniform in Li+” Image and Comment from Kwok, C. K., Marsico, G., Sahakyan, A. B., Chambers, V. S., & Balasubramanian, S. (2016). rG4-seq reveals widespread formation of G-quadruplex structures in the human transcriptome. Nat Meth, 13(10), 841–844. Retrieved from http://dx.doi.org/10.1038/nmeth.3965
Utilizing 2 facts:
they attached 3′ adaptors to the ends of RNA transcripts and subjected them to folding under different conditions as depicted above, and carried out reverse transcription which produced cDNA of different lengths that they subsequently characterized by PCR and next-generation-sequencing.
They found:
Only drawback of this paper is probably that it was done in vitro on HeLa cells which is a poor representation of what may be going on physiologically. However, it highlights some novel means by which G quadruplexes may regulate gene expression i.e through affecting miRNA binding or Argonaute association and influencing polyadenylation.
Some problems remain with targeting G quadruplexes for disease treatment. Namely how to achieve gene specificity given they are rather widely distributed. So far only one G quadruplex ligand (quarfloxin) reached PII clinical trials for neuroendocrine/carcinoid tumours but dropped out due to bioavailability issues. More structural investigations may be required to develop ligands that bind G quadruplexes with greater affinity. However, we have come a long way in showing how a “stupid” molecule like DNA can become devastatingly complex. And with their increasing ease of production, sequencing, manipulation and ability to assume complex structures that can be targeted by drugs, they have become intensely more interesting that proteins ever have.
Additional Sources:
Murat, P., & Balasubramanian, S. (2014). Existence and consequences of G-quadruplex structures in DNA. Current Opinion in Genetics & Development, 25, 22–29. http://doi.org/10.1016/j.gde.2013.10.012
G-Quadruplexes: A web of Functional Complexities by Janelle Vultaggio
Balasubramanian, S., Hurley, L. H., & Neidle, S. (2011). Targeting G-quadruplexes in gene promoters: a novel anticancer strategy? Nature Reviews. Drug Discovery, 10(4), 261–275. http://doi.org/10.1038/nrd3428
Banner image “Fairy DNA by kyz”
